
1. Giới thiệu chung
TinyML (Tiny Machine Learning) là một nhánh của trí tuệ nhân tạo (AI) tập trung vào việc triển khai các mô hình học máy trên các thiết bị phần cứng có tài nguyên giới hạn, ví dụ như vi điều khiển, cảm biến và các thiết bị IoT (Internet of Things) [1]. Các thiết bị như đồng hồ thông minh hoặc thiết bị theo dõi sức khỏe sử dụng TinyML để phân tích dữ liệu từ các cảm biến như đo nhịp tim, đếm bước chân và đưa ra các dự đoán hoặc thông báo mà không cần kết nối đến máy chủ đám mây. TinyML có thể được triển khai trên các cảm biến và thiết bị trong nhà thông minh để thực hiện các tác vụ như nhận diện giọng nói, phát hiện chuyển động, và điều khiển các thiết bị gia dụng tự động. Trong nông nghiệp, các cảm biến TinyML có thể giúp theo dõi môi trường, tình trạng đất đai và sức khỏe cây trồng, từ đó cung cấp dữ liệu cho việc quản lý nông nghiệp chính xác hơn. Với lĩnh vực chăm sóc sức khỏe từ xa, TinyML được sử dụng trong các thiết bị y tế cá nhân để giám sát liên tục và phân tích dữ liệu sức khỏe của bệnh nhân, giúp các bác sĩ có thông tin chính xác mà không cần bệnh nhân phải đến bệnh viện. Trong công nghiệp, TinyML được sử dụng để giám sát máy móc và thiết bị, phát hiện các dấu hiệu bất thường hoặc dự đoán sự cố hỏng hóc trước khi chúng xảy ra, giúp giảm thiểu thời gian ngừng hoạt động và chi phí bảo trì. TinyML có thể được tích hợp trong
Hình 1: Vị trí của TinyML trong lĩnh vực học máy và công nghệ nhúng
các hệ thống an ninh để nhận diện khuôn mặt, phát hiện tiếng động lạ, hoặc theo dõi hành vi bất thường trong thời gian thực.
Vì các mô hình TinyML hoạt động trên phần cứng có tài nguyên hạn chế, chúng thường tiêu thụ rất ít năng lượng, phù hợp cho các thiết bị chạy bằng pin. Hơn nữa, quá trình xử lý dữ liệu diễn ra trực tiếp trên thiết bị, thời gian phản hồi nhanh hơn nhiều so với việc gửi dữ liệu đến máy chủ đám mây để xử lý. Đặc biệt, dữ liệu được xử lý tại chỗ trên thiết bị, giảm thiểu rủi ro về bảo mật và quyền riêng tư so với việc gửi dữ liệu lên đám mây. Vì vậy, TinyML rất phù hợp đề phát triển các ứng dụng đặc thù, dữ liệu cần xử lý nội bộ như thiết bị quân sự. Tuy nhiên, với thiết bị phần cứng hạn chế về bộ nhớ, khả năng xử lý và tiêu thụ năng lượng thấp, các mô hình TinyML cần phải được tối ưu hóa để hoạt động hiệu quả trong những điều kiện này.
Điều khiển bằng giọng nói là một trong những tính năng phổ biến và được ưa chuộng trên nhiều thiết bị thông minh hiện nay. Thiết bị Alexa của Amazon có khả năng lắng nghe tiếng gọi theo thời gian thực [2]. Thiết bị có thể thức dậy và thực thi lệnh của người dùng gần như bất kỳ thời điểm nào và trong điều kiện có kết nối internet hay không. Google cũng có thiết bị với tính năng tương tự. Điểm nổi bật chung của các thiết bị nói trên đó là khả năng nhận diện “lệnh gọi” của người dùng theo thời gian thực và không yêu cầu có kết nối internet. Đây chính là những thiết bị ứng dụng TinyML đầu tiên trong thế giới thiết bị thông minh. Từ những phân tích trên có thể thấy ứng dụng mô hình học máy nhẹ đã được huấn luyện để thực hiện các dự đoán, phân loại theo thời gian thực là một xu hướng phát triển của thiết bị thông minh trong thời gian tới.
Mặc dù có tính ứng dụng cao, các nghiên cứu về nhận diện giọng nói bằng tiếng Việt trên các thiết bị IoT còn khá hạn chế ở Việt Nam [3]. Trong bài báo này, nhóm tác giả nghiên cứu ứng dụng mô hình trí tuệ nhân tạo nhẹ cho việc thực hiện nhận diện phân loại chữ số bằng tiếng Việt trên phần cứng có tài nguyên hạn chế làm cơ sở cho việc ứng dụng tính năng này trong các ứng dụng như quay số tự động, điều khiển bằng giọng nói hay giám sát bằng âm thanh. Bố cục của bài báo được trình bày như sau: Mục 2 sẽ trình bày về dữ liệu âm thanh và xây dựng tập dữ liệu âm thanh cho nhận diện chữ số bằng tiếng Việt. Mục 3 giới thiệu mô hình đề xuất, các tham số dùng cho khảo sát lựa chọn mô hình phù hợp. Kết quả mô phỏng, thực thi trên thiết bị phần cứng được phân tích làm rõ trong mục 4. Cuối cùng là kết luận của bài báo.
2. Xây dựng tập dữ liệu
Đối với các ứng dụng dựa trên học máy có giám sát, dữ liệu huấn luyện luôn là yếu tố vô cùng quan trọng ảnh hưởng đến chất lượng đầu ra dự đoán của mô hình. Trong phần này, quy trình thu thập dữ liệu âm thanh, kỹ thuật tiền xử lý và tạo tập dữ liệu sẽ được trình bày chi tiết.
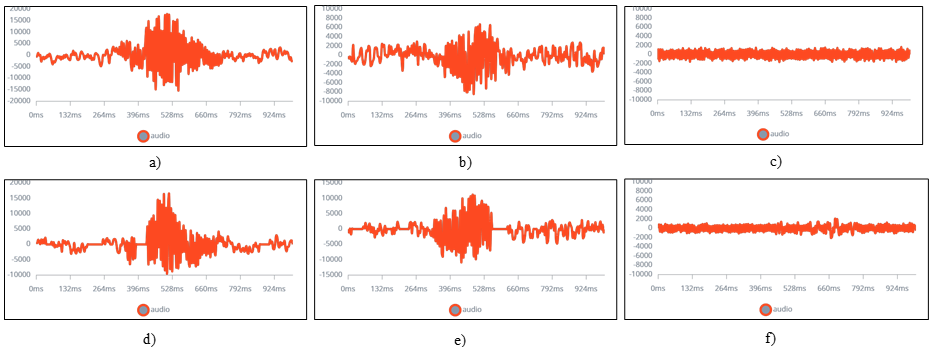
Đầu tiên, mỗi chữ số từ 0 đến 9 được ghi âm riêng biệt và lặp lại nhiều lần để tạo ra tập dữ liệu ban đầu. Hình 2 minh họa phổ âm tần của chữ số 1 và chữ số 4 được ghi âm bằng micro PDM và vi xử lý NRF52480. Dữ liệu này sau đó được vi xử lý truyền về máy tính thông qua giao thức UART. Tại đây, dữ liệu được chia nhỏ thành các mẫu có độ dài khoảng 800 ms. Ngoài ra, để có thể phân biệt được chính xác chữ số và các âm thanh còn lại như tiếng nói, tiếng ồn,.. dữ liệu âm thanh về môi trường xung quanh cũng được ghi âm và xử lý. Hình 2c,f minh họa dữ liệu âm thanh môi trường xung quanh được ghi lại và chia nhỏ theo độ dài 800 ms. Để đảm bảo huấn luyện mô hình, kích thước của dữ liệu phải đủ lớn. Bằng cách sử dụng các kỹ thuật giãn nở dữ liệu (Data augmentation[4]), từ mẫu âm thanh ban đầu có thể tạo ra 6 mẫu âm thanh mới khác nhau. Khi thay đổi tham số của kỹ thuật giãn nở dữ liệu, 6 mẫu âm thanh mới khác sẽ được tạo ra. Như vậy, với tập dữ liệu là 1017 mẫu ghi âm (920 mẫu cho các số từ 0 đến 9; 97 mẫu cho âm thanh môi trường) và sử dụng các tham số khác nhau tập dữ liệu cuối cùng tạo được là 12204 mẫu dữ liệu. Mỗi chữ số sẽ có khoảng 1104 mẫu, đảm bảo số lượng mẫu cho thực hiện huấn luyện mô hình nơ-ron sâu.
Đối với các mô hình học máy, việc xử lý trực tiếp trên âm thanh gốc bao gồm hàng nghìn mẫu sẽ làm tăng độ phức tạp của mô hình, tăng thời gian xử lý và tốn tài nguyên phần cứng. Vì vậy, việc xử lý dữ liệu thô bằng các mô hình học máy là không thực tế và không phù hợp với các thiết bị có tài nguyên phần cứng hạn chế. Trong bài báo này, nhóm tác giả lựa chọn biến đổi dữ liệu âm thanh gốc sang dạng dữ liệu ảnh phổ MFCC (Mel Frequency Cepstral Coefficients) [5] cho mục đích phân loại chữ số. Các tham số cho xử lý tín hiệu về dạng MFCC: frame length 0.02, frame stride 0.02, filter number 32, FFT length là 256. Kết quả đầu ra là một dạng dữ liệu mới với kích thước là 13×26 như minh họa trong Hình 3c,d.

3. Mô hình TinyML đề xuất
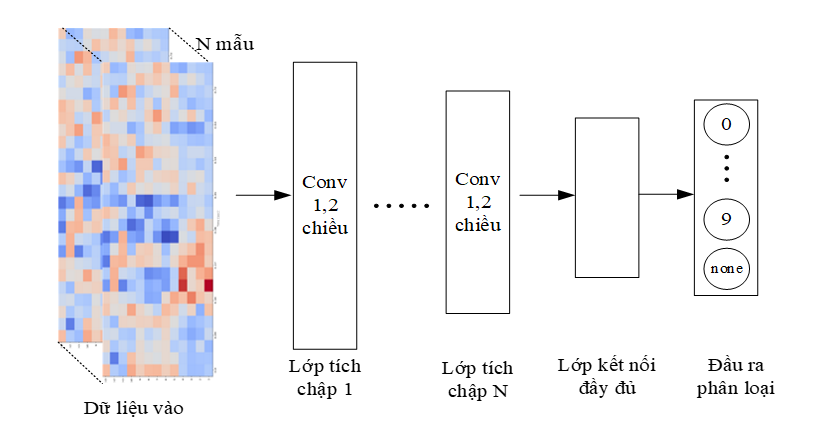
Đối với tín hiệu âm thanh sau khi đã được chuyển về dạng phổ MFCC, đặc trưng của dữ liệu này rất giống với dữ liệu hình ảnh. Chính vì vậy, nhóm tác giả lựa chọn và đề xuất mô hình dựa trên kiến trúc mạng tích chập CNN. Mạng tích chập CNN là một trong những kiến trúc được sử dụng rộng rãi trong nhiều ứng dụng liên quan đến thị giác máy tính, phân loại hình ảnh [6]. Hình 4 mô tả kiến trúc đề xuất với dữ liệu đầu vào, các lớp tích chập, một lớp kết nối đầy đủ và một lớp đầu ra gồm 11 nhãn. Trong đó dữ liệu đầu vào là ảnh phổ MFCC có kích thước là 13×26.
Việc lựa chọn số lượng và kích thước của bộ lọc được thực hiện thông qua thử nghiệm nhiều giá trị khác nhau (Grid search[7]) sau đó xác định hiệu năng phân loại phù hợp. Ngoài ra, tham số mô hình cũng được xác định dựa trên tham số của kỹ thuật tiền xử lý dữ liệu. Chi tiết các tham số cho khảo sát mô hình tối ưu được trình bày trong Bảng 1.
Bảng 1:
| STT | Tham số mô hình | |||
|---|---|---|---|---|
| Loại | Kích thước bộ lọc | Kích thước lõi | Tỉ lệ dropout | |
| 1 | Conv1d | 8x16x32 | 3×3 | 0.5 |
| 2 | Conv1d | 8x16x32x64 | 3×3 | 0.25 |
| 3 | Conv2d | 16×32 | 3×3 | 0.5 |
| 4 | Conv2d | 8×16 | 3×3 | 0.5 |
| 5 | Conv2d | 24×48 | 3×3 | 0.5 |
| 6 | Conv2d | 8x16x32 | 3×3 | 0.5 |
| 7 | Conv1d | 16x32x64x128 | 3×3 | 0.25 |
| 8 | Conv1d | 16x32x64 | 3×3 | 0.5 |
Tiếp theo, nhóm tác giả thực hiện huấn luyện mô hình với các tham số liệt kê trong Bảng 1. Kết quả của các mô hình trên sẽ được lựa chọn để xác định mô hình tối ưu cho thiết bị. Chi tiết kết quả được trình bày trong mục tiếp theo.
4. Đánh giá thử nghiệm
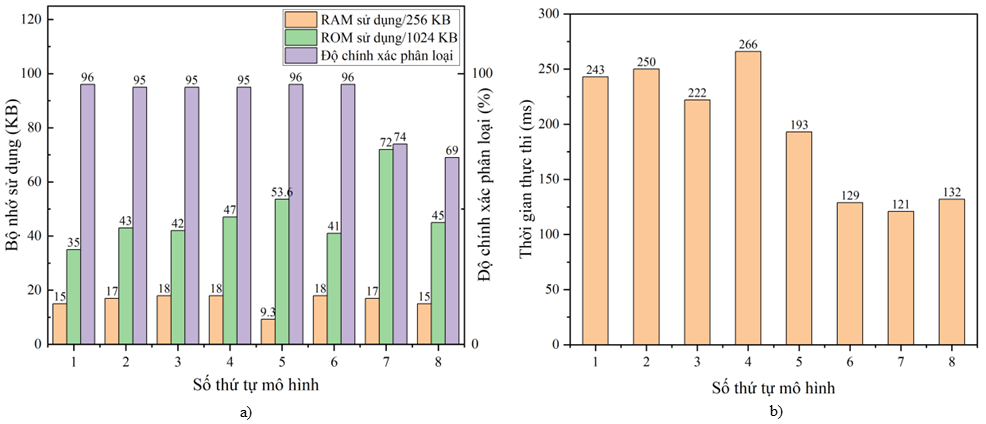
Tất cả các thí nghiệm trong bài báo này được thực thi trên nền tảng Edge Impulse [8]. Kết quả phân loại, thời gian thực thi cũng như tài nguyên phần cứng sử dụng được thể hiện trong Hình 5. Có thể thấy các mô hình thứ tự từ một đến sáu đều cho kết quả phân loại cao, xấp xỉ 96%. Với mô hình 7, 8, khi thực hiện bộ tích chập 1D và dữ liệu MFCC 32 bộ lọc cho kết quả giảm mạnh, chỉ còn khoảng 69%. Nhận thấy mô hình số 5 với hai lớp tích chập 2D, kích thước bộ lọc lần lượt là 24 và 48, hiệu quả phân loại cũng như thời gian thực thi đảm bảo cân bằng và phù hợp với ứng dụng nhận diện giọng nói (độ chính xác là 96%, thời gian thực thi là 193 ms). Hơn nữa, mô hình này có bộ nhớ RAM sử dụng bằng 50% so với mô hình 6, trong khi bộ nhớ RAM của vi điều khiển là tài nguyên quan trọng, nhóm tác giả ưu tiên lựa chọn mô hình có bộ nhớ RAM nhỏ hơn để có tài nguyên bộ nhớ cho các tác vụ xử lý khác như truyền nhận dữ liệu. Chính vì vậy, mô hình số 5 được sử dụng và gọi tắt là mô hình đề xuất trong toàn bộ nội dung còn lại của bài báo.
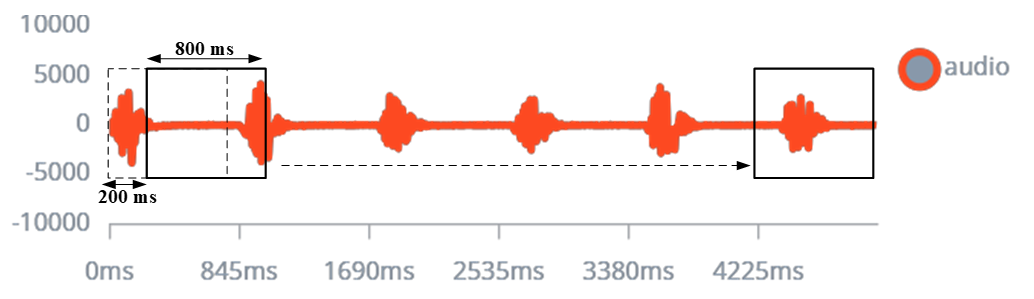
Trong thí nghiệm tiếp theo, nhóm tác giả thực hiện lấy mẫu dữ liệu âm thanh thu âm chuỗi số Bốn liên tiếp, với khoảng cách giữa các lần nói là nhỏ hơn 1 giây. Thí nghiệm này đánh giá khả năng phân loại chữ số trong một chuỗi âm thanh. Với độ dài mẫu dữ liệu đánh giá là 4200ms, bước nhảy cho mỗi lượt phân loại là 200ms, mỗi mẫu dữ liệu đầu vào là 800ms. Tổng cộng 22 lượt phân loại cho chữ số Bốn đã được thực hiện. Quan sát kết quả trong Bảng 2 nhận thấy, mô hình đề xuất thực thi với độ chính xác cao. Cụ thể, có tổng cộng 20/22 lượt phân loại đúng đầu ra số Bốn, đạt tỉ lệ 90.9%.
| Mốc thời gian | Thứ tự cửa sổ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | None |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 200 | 2 | 0 | 0.95 | 0 | 0 | 0.05 | 0 | 0 | 0 | 0 | 0 | 0 |
| 400 | 3 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 600 | 4 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 800 | 5 | 0 | 0.03 | 0 | 0 | 0.97 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1000 | 6 | 0.8 | 0.05 | 0 | 0 | 0.15 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1200 | 7 | 0 | 0.26 | 0 | 0 | 0.74 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1400 | 8 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1600 | 9 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1800 | 10 | 0 | 0.04 | 0 | 0 | 0.96 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2000 | 11 | 0 | 0 | 0 | 0 | 0.99 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2200 | 12 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2400 | 13 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2600 | 14 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2800 | 15 | 0.01 | 0.02 | 0 | 0 | 0.97 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3000 | 16 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3200 | 17 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3400 | 18 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3600 | 19 | 0.05 | 0 | 0 | 0 | 0.95 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3800 | 20 | 0 | 0.07 | 0 | 0 | 0.93 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4000 | 21 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4200 | 22 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
Số lượt phân loại sai rơi vào số Một và số Không, tỉ lệ 2/22 (9.09%). Kết quả trên cho thấy mô hình đề xuất có khả năng nhận diện tốt chữ số Bốn so với các số còn lại cũng như âm thanh môi trường. Tuy nhiên, kết quả cũng cho thấy mô hình thực hiện phân loại chưa tốt giữa số Một, số Bốn và số Không, giá trị phân loại số Một trong một số trường hợp là rất cao (0.95 cho số Một và 0.005 cho số Bốn). Nguyên nhân chính là do kích thước cửa sổ và khoảng cách giữa các lần phổ số 4 xuất hiện chưa được tối ưu. Vì vậy, xảy ra một số trường hợp cửa sổ trượt sẽ chứa một phần thông tin của phổ số Bốn, dẫn đến mô hình phân loại sai. Đây cũng chính là hướng nghiên cứu tiếp theo của bài báo nhằm nâng cao độ chính xác phân loại giữa các số có phổ MFCC giống nhau như số Một và số Bốn, khắc phục hiện tượng cửa sổ trượt. Hơn nữa, trong nghiên cứu tiếp theo, nhóm tác giả thực hiện đánh giá chi tiết hiệu quả của mô hình đề xuất trên bộ vi xử lý Arm Cortex-M4F thay vì thực thi trên môi trường mô phỏng Edge Impulse.
5. Kết luận
Trong bài báo này, nhóm tác giả đã giới thiệu ứng dụng của TinyML trong nhận diện chữ số tiếng Việt theo thời gian thực bằng giọng nói. Sử dụng TinyML được tối ưu hóa cho các thiết bị có tài nguyên hạn chế và vi điều khiển tiêu thụ ít năng lượng, mô hình đề xuất đã đạt được nhận diện chữ số chính xác và nhanh chóng. Các kết quả thực nghiệm từ mô phỏng vi điều khiển ARM Cortex-M4F đã chứng minh tính hiệu quả của mô hình đề xuất, độ chính xác phân loại lần lượt là 96% và 90% với dữ liệu âm thanh chữ số đơn và dữ liệu âm thanh chuỗi số liên tiếp. Kết quả trên cho thấy những triển vọng mới cho các ứng dụng điều khiển bằng giọng nói trong môi trường có tài nguyên hạn chế, đặc biệt là trong ngữ cảnh ngôn ngữ tiếng Việt.
Tài liệu tham khảo
[1] Han, Hui & Siebert, Julien. “TinyML: A Systematic Review and Synthesis of Existing Research”, 269-274. 10.1109/ICAIIC54071.2022.9722636, 2022.
[2] Hoy, Matthew B. “Alexa, Siri, Cortana, and More: An Introduction to Voice Assistants.” Medical Reference Services Quarterly 37 (1): 81–88. doi:10.1080/02763869.2018.1404391, 2018.
[3] Thực, Hoàng. “Nghiên cứu thiết kế mô hình điều khiển xe robot bằng giọng nói với Raspberry Pi 4”, TNU Journal of Science and Technology. 229. 200-205. 10.34238/tnu-jst.9665, 2024.
[4] J. Salamon and J. P. Bello, “Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification,” in IEEE Signal Processing Letters, vol. 24, no. 3, pp. 279-283, doi: 10.1109/LSP.2017.2657381, March 2017.
[5] Sidhu, Manjit & Latib, Nur & Sidhu, Kirandeep. “MFCC in audio signal processing for voice disorder: a review. Multimedia Tools and Applications”, 1-21. 10.1007/s11042-024-19253-1, 2024.
[6] Lecun, Yann & Bengio, Y. “Convolutional Networks for Images, Speech, and Time-Series. The Handbook of Brain Theory and Neural Networks”, 1995.
[7] Claesen, Marc & Simm, Jaak & Popovic, Dusan & Moreau, Yves & De Moor, Bart. “Easy Hyperparameter Search Using Optunity”, https://doi.org/10.48550/arXiv.1412.1114, 2014.
[8] Hymel, et al., “Edge Impulse: An MLOps Platform for Tiny Machine Learning”, 10.48550/arXiv.2212.03332, 2022